- Published on
Cache Eviction Policies in Storage Engines
- Authors

- Name
- Dev Canary
- @kibandiian
Cache Eviction Policies in Storage Engines
Introduction
Caching is a concept in Computer Science that stores frequently accessed items in a fast-access volatile storage, to improve performance. Retrieving data from a cache, rather than a more durable storage layer, improves response time and reduces computational needs.
Why is volatile storage faster?
Volatile storage consists of Random Access Memory (RAM), registers and CPU caches. They are used to store instructions and recently accessed data to prevent having to retrieve it from main memory or persistent storage.
Persistent storage consists of Hard Disk Drives(HDD) and Solid State Drives (SSD), which persist data even after power failures. HDDs require disk rotation and mechanical head movements to position the head to the right location in order to read data from a sector - the smallest readable unit. This operation is expensive and slow.
SSDs organize data into pages, which is the smallest unit that can be written or read. This is much faster than HDDs, but still inefficient since in order to read even a few bits you will have to read the whole page - which can be several KiloBytes.
Due to this, operating systems have block device abstraction that buffers I/O operations and maintains a page cache to reduce writes. Most databases bypass this on linux and use their own buffer management. However, this is frowned upon by the OS community (https://yarchive.net/comp/linux/o_direct.html, https://www.p99conf.io/2025/05/22/databases-linux-page-cache).
Volatile memory is readily available and with low latency (as low as ~5ns for page cache). The downside however, is that it pretty expensive and you can only keep a limited size dataset.
Cache Eviction
Due to the limited space, cached items that are no longer needed have to be removed to allow newer, more urgently needed items to be added. This process is called eviction. In storage engines, it may also involve flushing dirty pages to disk. Eviction policies decide what items to evict based on a determined scheme. Paired with this is admission policies which determine what items to admit into the cache. Both of these processes need to be efficient to ensure the benefits of a cache are not outweighed by the computational and storage costs. The space used to determine what items to be admitted or evicted is called cache metadata.
Let us look at some of these policies:
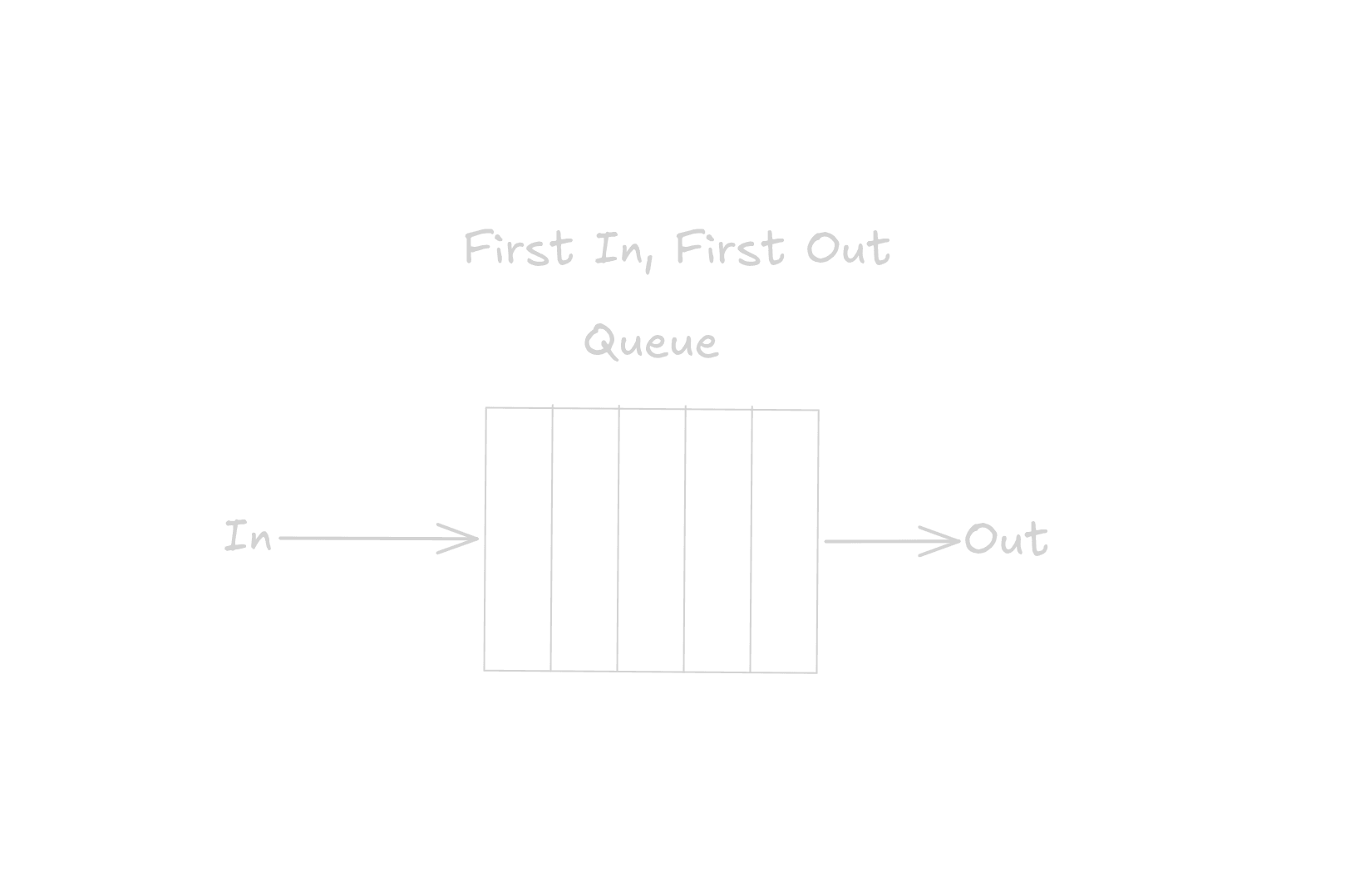
First In, First Out (FIFO)
First In, First Out(FIFO) uses a queue and adds items(PageIDs) to the end of the queue. When the queue is full and a new items needs to be added, the last item is evicted regardless of whether it's needed or not.
Needless to say this is the most naive eviction policy as it only accounts for when an item was first accessed.
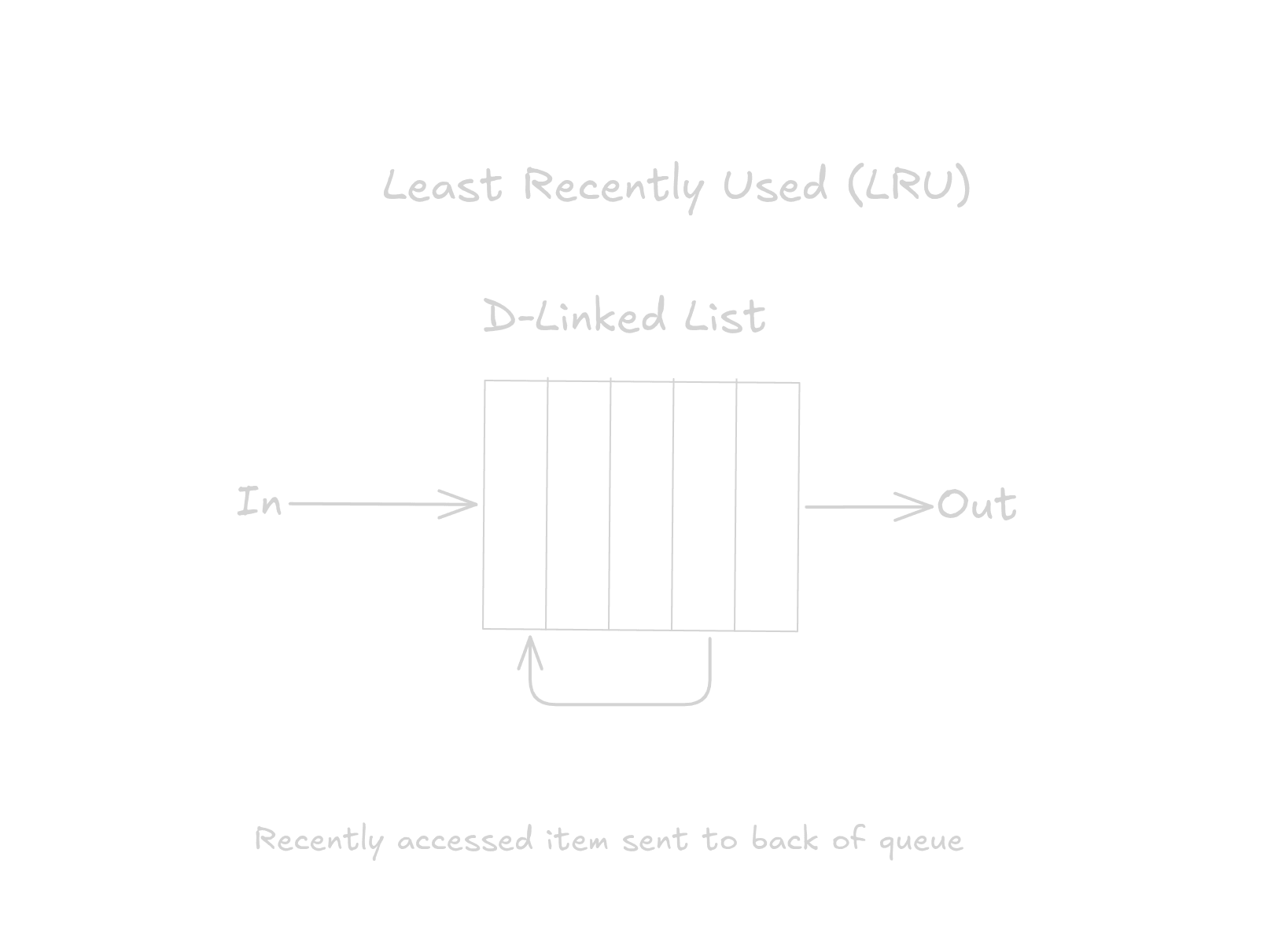
Least Recently Used (LRU)
An extension of FIFO, LRU also uses a data structure based on insertion order but allows you to bring an item to head of the queue if recently accessed. This allows you to evict the least recently accessed item, relative to other items in the queue.
There are variations of LRU-based cache eviction policies like the Segmented LRU(SLRU) which captures recent popularity by distinguishing temporarily popular items from items only accessed once in a short window.
It does this by having two fixed size LRU segments , probation and protected segments. Any new item is added to the probation segment and a subsequent access to the same item moves it to the protected segment. If the probation segment is full, an item is evicted based on the LRU policy. Likewise, if the protected segment is full, an item is evicted. However, evicted items from the protected segment are added back to the probation. This allows temporarily popular items in the protected segment to be stored for longer than less popular items. We will make use of this later on.
Another variation is the LRU-K, which keeps track of the last K accesses and uses that to estimate the temporal locality and frequency of an object over a longer time window. For this blog, we will not go into LRU-k but you can check out the LRU-k paper if you are interested in knowing more.
CLOCK algorithm
Clock algorithms are a compact, cache-friendly and concurrent alternative to LRU and it is widely used on Linux as well as PostgreSQL.
They use a circular buffer where each node contains a reference to a page and an access bit. It also has a hand pointer with a reference to the current node. Whenever a page is accessed, the access bit is set to 1. The algorithms goes through the circular buffer and checks access bits:
- If access bit is 1, it is set to 0.
- If access bit is 0, the page gets scheduled for eviction.
Suppose we have the following state of the circular buffer and we want to insert page ID 5.
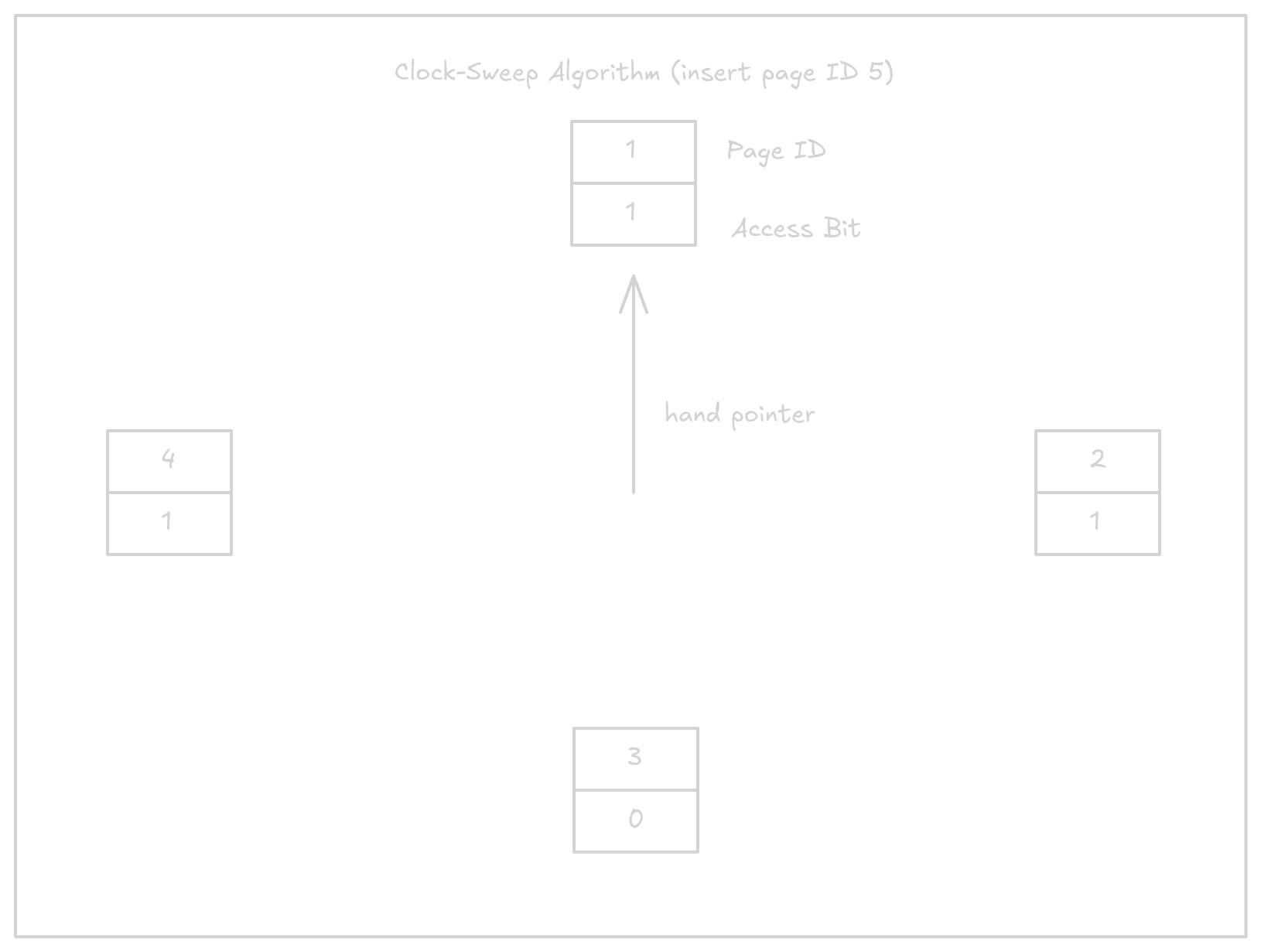
- The hand pointer moves clockwise, starting from page ID 1 and sets access bit to 0.
- Moves to the next, page ID 2 and sets access bit to 0.
- Moves to page ID 3 and the access bit is already 0. This page is evicted and page ID 5 is added with its access bit set to 1.
The final version looks like this:
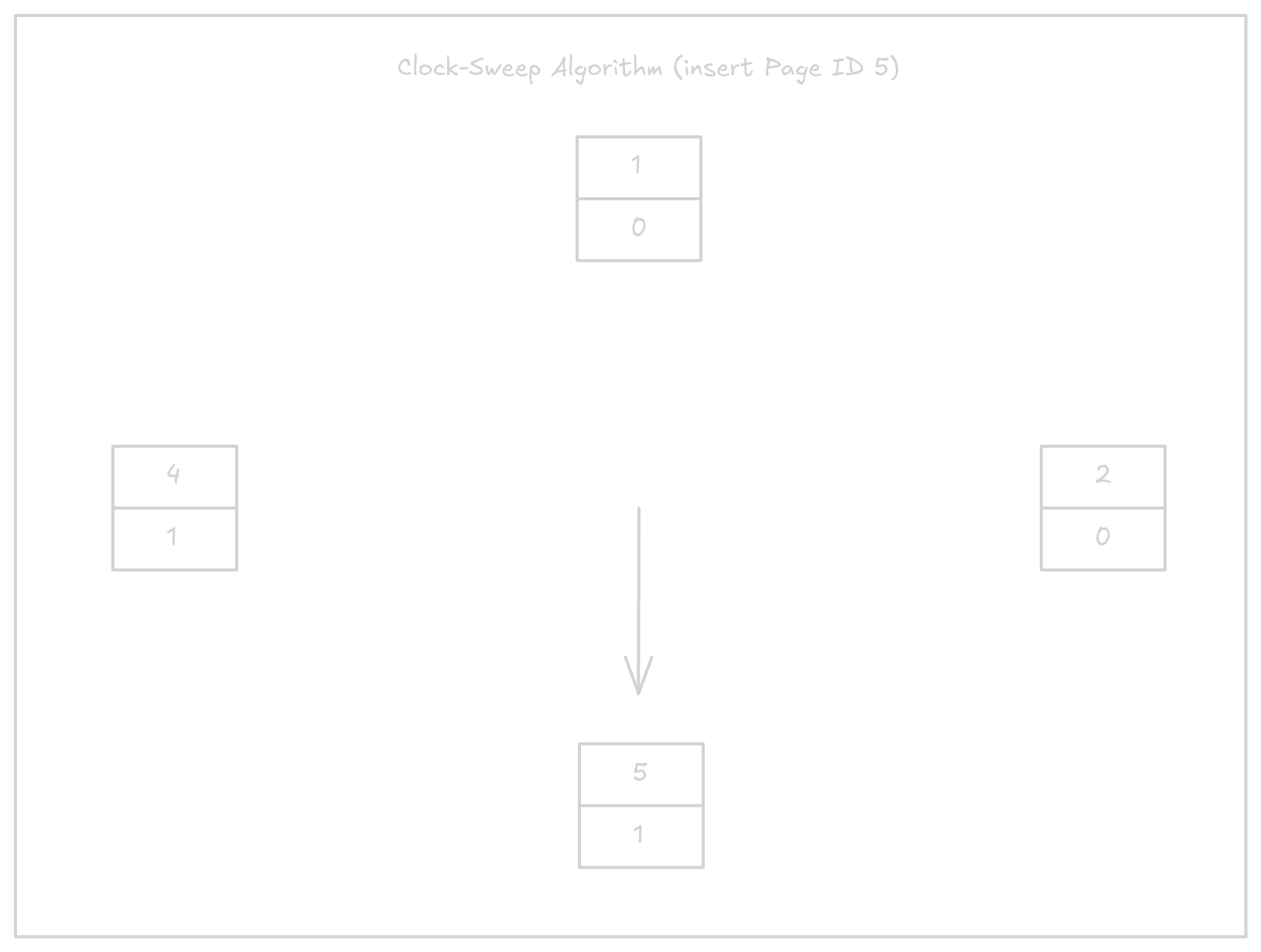
The advantage of circular buffers is that they do not require additional locking mechanisms.
Least Frequently Used (LFU)
In certain scenarios, recency may not be the best strategy. It might be more practical to use frequency to predict the probability of a page being accessed in future. This can be done by tracking reference events rather than page-in.
LFU eviction policy evicts items that have the lowest access rate. This is done by tracking accesses to cache items and using this to decide which ones to evict (and admit as we will see later). The downside is that this metadata may grow in size and complexity, and access patterns may be skewed. A popular item now may not be popular next week and will not be a necessary item to keep then.
Some variations of LFU utilize an aging mechanism on a limited-size window to limit the size of metadata and adapt caching and eviction to reflect more recent patterns. An example of this is the Window TinyLFU scheme. In order to understand this, let’s first have a look at its predecessor - TinyLFU.
TinyLFU
TinyLFU is a frequency-based page-eviction and admission policy that utilizes a space efficient data structure that estimates the frequency of items on large set of recently accessed items. This means the metadata can occupy single memory page and remain pinned in physical memory allowing for fast manipulation.
TinyLFU structure
TinyLFU uses approximation sketches to keep track of the frequency of items, and this information is used to make decisions on what item to admit or evict.
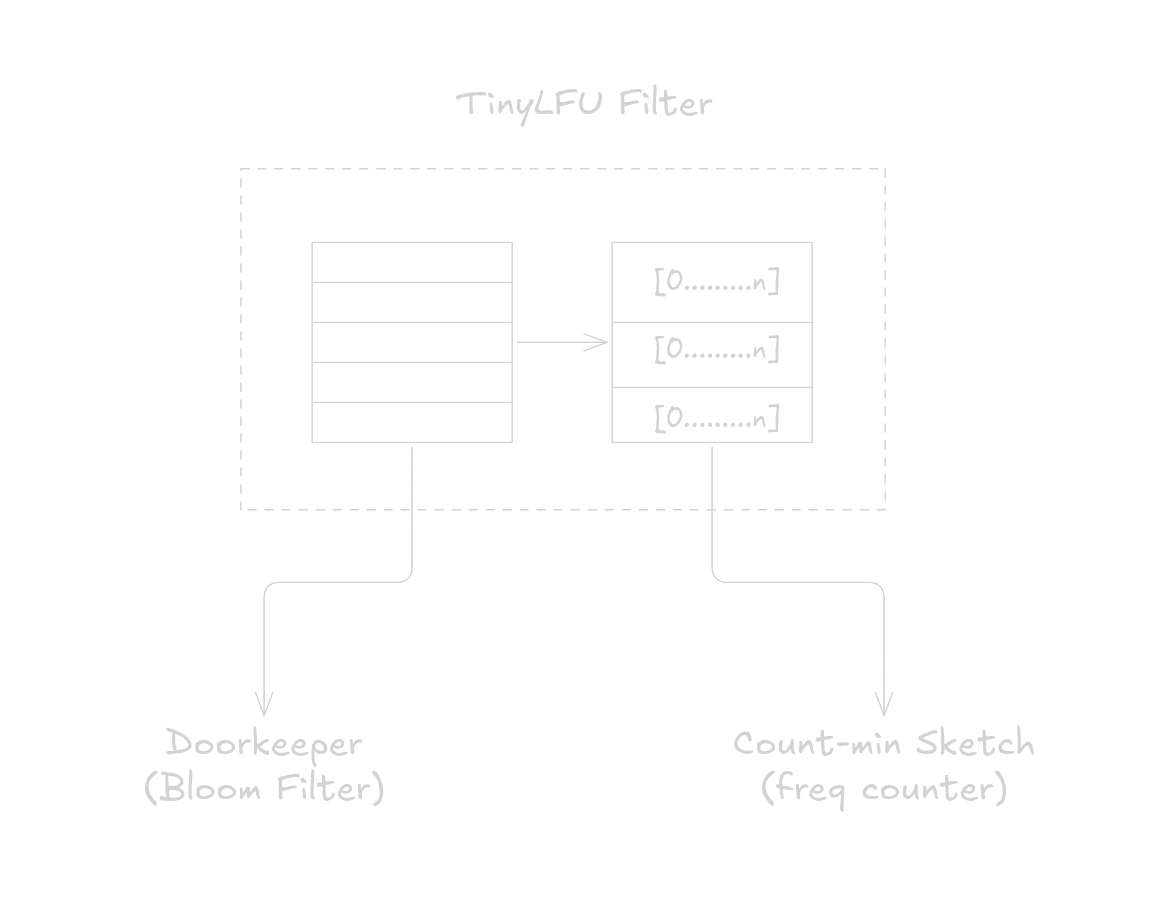
The main structure is a Count-min Sketch which contains counters in a 2D array, while a Doorkeeper - a bloom filter - is placed infront of the main structure to ensure that only popular items are tracked be the main structure.
Let’s have a look at how each of these structures work.
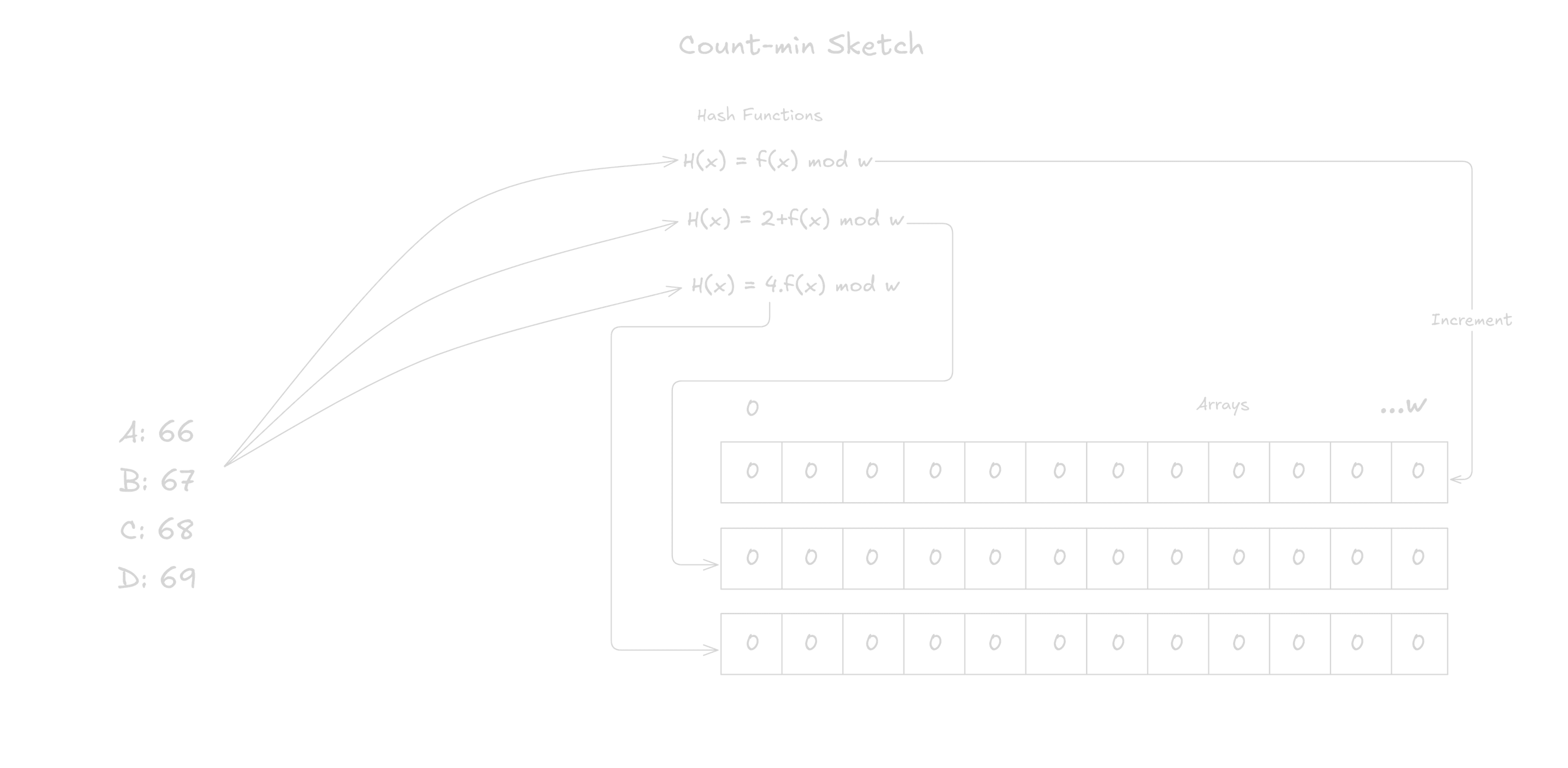
Count-min Sketch (CMS)
A Count-min Sketch is a probabilistic data structure that is used to keep count of information in a fixed-size data structure. It is widely used in IP networking, machine learning, distributed computing and signal processing.
It contains a 2D array of width and rows, with all counters initialized to zero, and number of hash functions, equivalent to , used to determine the positions to fill.
When adding an item, it is passed through the hash functions, which yield the indices in the 2D array to increment. Each index in the array is then incremented by 1. For efficiency, the hash functions do not have to be cryptographic but need to be different to yield a unique insertion index.
When retrieving the count of an item, it is passed through the same hash functions and the lowest count is chosen. The accuracy of the sketch is determined by the size of and . A large 2D array yields a lower error rate.
Tuning the Count-min Sketch
To determine the value of and , we need two parameters: Error rate () and probability ().
To get :
Where is the base of the natural logarithm .
Some applications round this to resulting in
For the original paper presents this formula:
where is per row failure probability, selected by the user.
Most common choices according to the original paper and 2011 paper for is or . Each yields a different result.
If you set , the resulting formular is:
if you choose :
For simplicity, we will set , hence .
Suppose we want a sketch with an error rate of 0.1% and a certainty of 99.9%:
To get and :
Our sketch will have a width of 2000 and 10 hash functions.
Suppose we use 16 bit counters in each slot, the total size of the sketch will be:
Our sketch will be .
A more accurate sketch () will require a larger array hence requiring more space. This is a tradeoff one has to make while designing their CM Sketch.
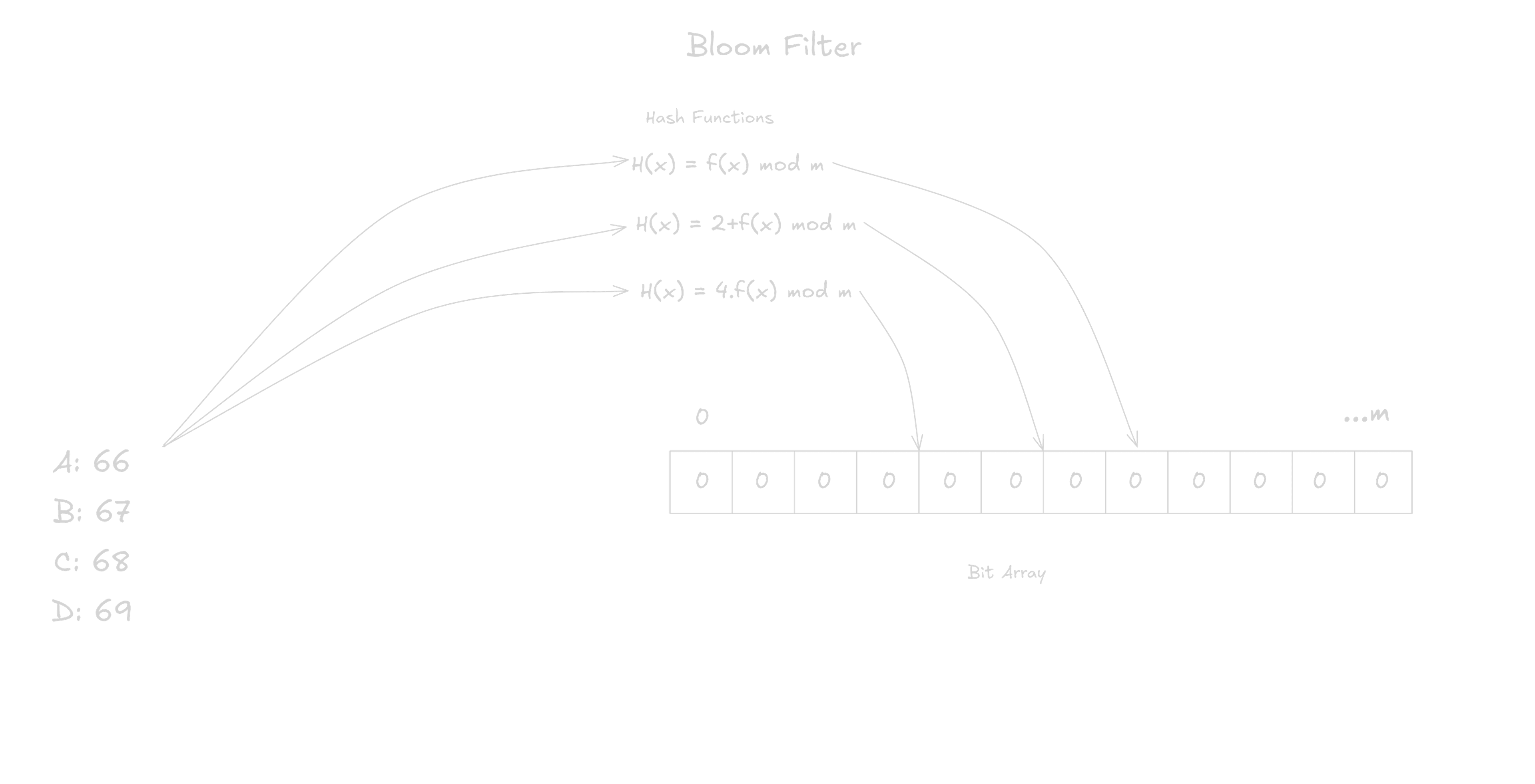
Doorkeeper (Bloom Filter)
The doorkeeper is a mechanism that reduces counter allocations to tail objects. In most scenarios, accessed items tend to not be the popular ones and counting items not likely tot appear again will increase the size of counters. A doorkeeper utilizes a bloom filter and is placed infront of the main structure to prevent one-off accesses from being counted by the CMS.
A bloom filter is a probabilistic data structure that tests if an element is a member of a set. It uses an array of bits, initialized to 0, and hash functions. Every item added is passed through the hash functions and the resulting indices give us the position in the array where the bit is set.
When checking an item, it’s fed through the hash functions and the bits in the resulting indices are retrieved. If any of the bits is zero, the item definitely does not exist.
The doorkeeper uses this to check if an item has been set before. If not, the item will be added to the bloom filter but not to the main structure else it will be added to the main structure. This ensures new items do not immediately get allocated a counter.
Reset Operation
To keep the sketch fresh, TinyLFU uses a reset method. Everytime an item is added, a counter is incremented. When the counter reaches a specified sample size (), all counters in the CMS are divided by 2 and the Doorkeeper is cleared. This reduces the space cost and maintains accuracy while utilizing the same space.
While performing the reset operation, we may encounter a truncation error since we are using integer division. The truncation error affects the count by . This means that a larger sample size will reduce the truncation error.
Window TinyLFU (W-TinyLFU)
According to the official paper, the authors encountered some challenges when integrating TinyLFU with Caffeine, a high-performance Java caching library. Items that experienced “sparse bursts” did not build enough frequency to remain in the cache and ended up being evicted. This resulted in repeated cache misses.
An optimization to TinyLFU, Window TinyLFU, introduced two cache areas. A window cache that uses a LRU eviction policy and a main cache that utilizes SLRU eviction policy and TinyLFU admission policy. The window cache occupies of the space and main cache takes up . In the main cache, the first section (probation) occupies of the space for non-hot items and the second section occupies of the main cache space, holding hot items.
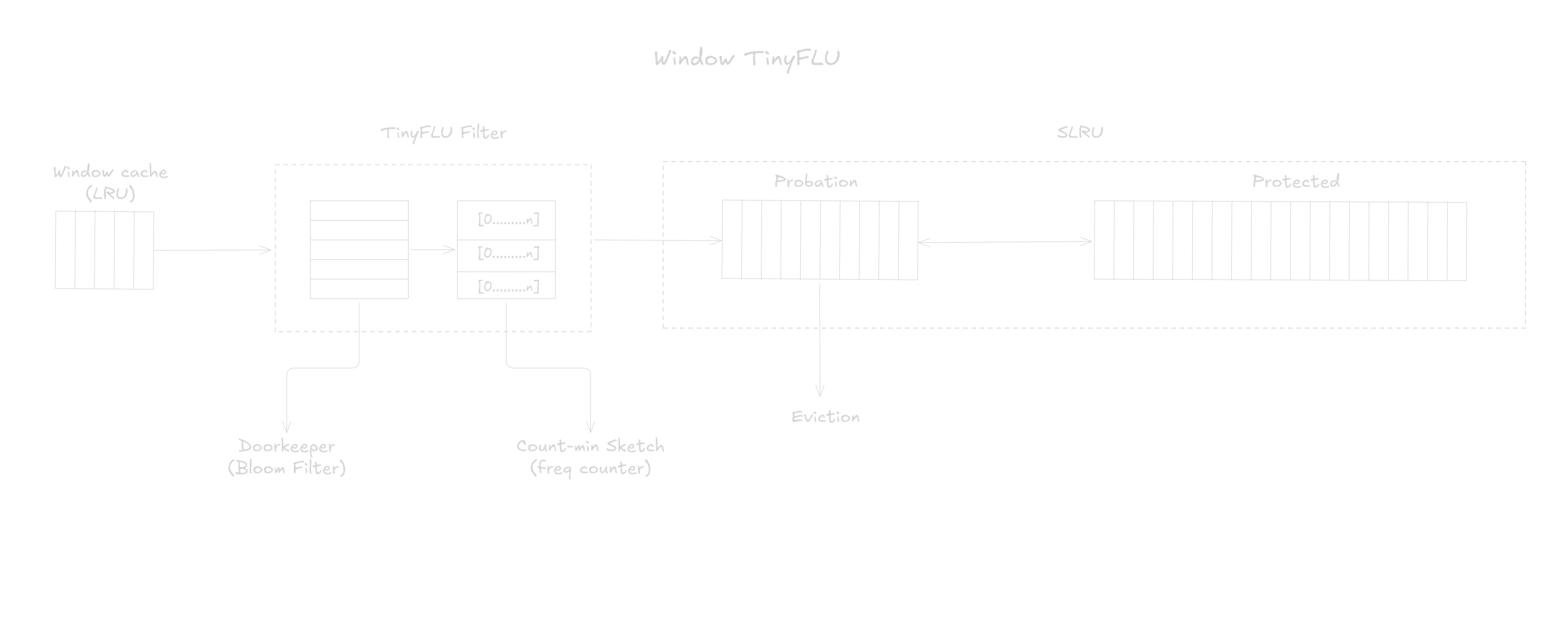
A new item is always added to the window cache. If the window cache is full, a victim is chosen by the LRU policy and is compared - using TinyLFU filter - to the victim on the probation segment. If the window cache’s victim has a higher count than the main cache's victim, the main cache victim is evicted and the window cache’s victim is added to probation. Otherwise, the window cache victim is evicted.
W-TinyLFU aims to have a scheme that behaves like TinyLFU for LFU workloads while still being able to exploit LRU patterns such as bursts.
Benchmarks in Augmented Caches
The paper compares results obtained by Augmenting W-TinyLFU with caches to other state of the art schemes like ARC and LIRS, ranging from YouTube traces to OLTP databases. In summary, W-TinyLFU produced comparable performance to state of the art schemes and outperforms LRU and LIRS while being slightly better than ARCS in smaller caches. For more detailed report on benchmarks including visual representation of the results, I would recommend checking out section 5 of the paper linked in the references section.
W-TinyLFU implementation
W-TinyLFU has been implemented in the popular Caffeine Java caching library and is actively in use.
I have also gone ahead and worked on a Golang implementation. You can find the code base here
Conclusion
We have checked out various eviction and admission policies widely used by storage engines and caching libraries. Each one has their own advantages and disadvantages and it’s upon the engineer to chose one with an understanding of the tradeoffs.
It is recommended to read the papers attached below to further your understanding of the concepts described in this article.
Thanks for reading. Have any questions, corrections or projects you want to tackle? Feel free to get in touch [email protected] or book a consultation at devcanary.com.
References
- TinyLFU White paper by Gil Einziger and Roy Friedman.
- Count-min 2011 sketch paper.
- Count-min sketch original paper
- Redis Blog on CMS.
- Database Internals by Alex Petrov.
- PostgreSQL page replacement algorithm.
- W-TinyLFU GitHub repo.